
The AI-RAN industry alliance was announced in early 2024, backed by several operators, vendors and research partners. This was a natural spin-off from the Open RAN alliance which brought the possibility of a cloud native RAN at the cell site (or close enough).
The initial focus areas of AI RAN are the following:
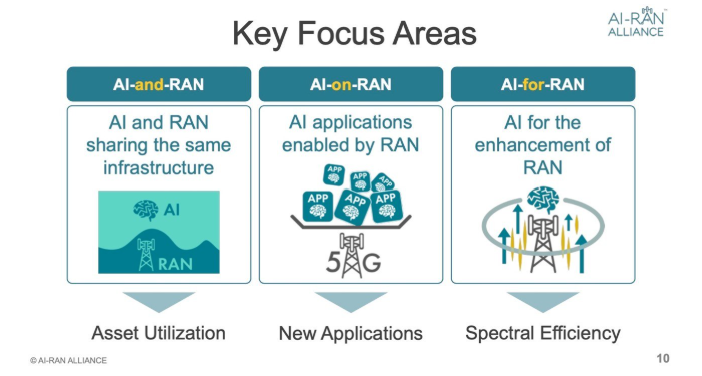
- AI for RAN: perhaps the most intuitive and familiar use case, this addresses opportunities to leverage Machine learning (ML) and Artificial Intelligence (AI) to improve the efficiency, performance and capacity of Radio Access Networks (RAN). While this is not entirely new, since the days of Self Optimizing Networks (SON) there has been a lot of products providing some level of AI based automation for optimizing networks, managing power consumption. More recently the usage of AI/ML in the air interface modeling, channel estimation, large scale MIMO promises significant improvement in RAN capacity and performance.
The monetization here is through inherent improvements to the RAN capacity and cost reductions (power savings, possibly less resources to serve the same capacity etc.) - AI on RAN: is about utilizing RAN infrastructure not only for communication but also as a host and enabler for AI application, especially at the network edge, for both internal and external stakeholders.
Examples of the identified use cases are:- Joint service bundles: Combining AI applications with core network offerings (ex: AI-powered video analytics for smart cities, industrial IoT, AR/VR).
- Telco-specific LLMs and AI tools: Operators are collaborating to develop multilingual, domain-adapted LLMs and host third-party AI services leveraging the RAN’s geographic reach and context.
- AI-as-a-Service (AIaaS): Running AI workloads (e.g., large language models, GenAI, real-time analytics) on the RAN’s edge computing resources, serving both telco internal operations (customer service, marketing, fraud detection) and external enterprise customers.
Monetization is likely through marketplace applications similar to those allowed by the RAN Intelligent Controller (RIC) in the Open RAN architecture. B2B and industry specific applications will continue to be a possible monetization avenue here as well.
- AI and RAN: This use case is focused on the architectural convergence and joint resource utilization of AI and RAN workloads on shared infrastructures, optimizing capital and operational expenditures and unlocking new monetization opportunities. The difference here is that AI and RAN share the same infrastructure but not the same application intelligence while AI on RAN are utilizing the RAN application intelligence. The use case is simply to use the RAN infrastructure (baseband processing / GPU) as an edge data center that can host any kind of AI/GenAI workload and co-exist with the RAN workload through multi tenancy.
In the rest of the article, I will focus on the business case for this scenario.
AI training and inferencing
In general, the resources needed for AI training are very different from those needed at the inferencing stage. AI training involves feeding the AI algorithm huge amounts of data in order so that it builds its internal weights which define its model of the data. This model allows it later to “predict” or “infer” what the new data point should correspond to as an output. Think of AI as a machine that builds a mathematical function, it trains on a lot of data to develop that function, then you deploy it on new data (it has not seen before) and the function is used to predict or infer the expected output.
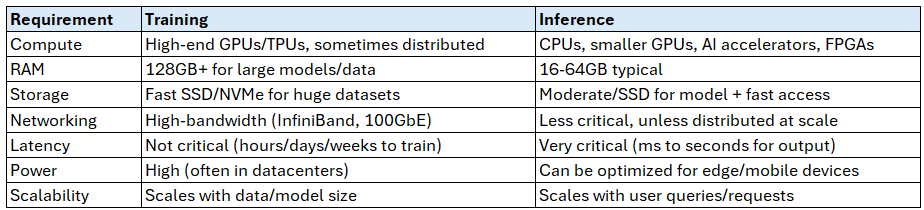
So naturally AI model training is much more demanding and perhaps more suited to a cloud data center, while AI inferencing could be more approachable form an Edge node performance wise.
Edge AI: AI inference on or near the device where data is generated (e.g., sensors, cameras, phones, gateways, RAN cell site). Running AI on the edge delivers lower latency, stronger privacy, and reduced bandwidth costs by processing data closer to the end device
Cloud AI: AI workloads run in remote data centers with elastic compute/storage; data is transmitted to/from devices. Cloud AI offers superior scalability and compute for large models and centralized management; most modern systems combine both in hybrid patterns where time‑critical inference is local and heavy training/analytics remain in the cloud.
AI workloads in “AI and RAN”
“AI and RAN” architectures are designed to support both AI training and AI inferencing workloads on shared infrastructure. The goal is to dynamically allocate and orchestrate resources such as GPUs between demanding AI tasks and real-time RAN functions. Here are some key considerations:
- Training Workloads: The AI-RAN reference architecture specifies that the platform must be capable of handling the offline training of large AI models (typically performed in centralized data centers or the cloud), as well as online training and adaptation at the network edge for more immediate, localized needs. This is enabled by using software-defined, GPU-accelerated hardware in the RAN infrastructure.
- Inference Workloads: The same infrastructure also supports the deployment (inference) of AI models in real time, particularly for latency-sensitive and mission-critical tasks needed at the edge, such as network optimization, predictive maintenance, or serving customer-facing AI applications.
- Dynamic Orchestration: AI-and-RAN platforms use advanced orchestration frameworks to assign resources in real time according to the specific requirements of either training or inference workloads, maximizing resource utilization and efficiency.
Business models for “AI and RAN”
The telecom industry has been notoriously challenged as it is by heavy CAPEX investments and OPEX heavy networks, so what business models would make this “AI for RAN” model work? Keeping in mind that the hardware pushed for this model is most likely going to be GPUs (mainly from Nvidia at this stage) which are even more expensive than RAN or ORAN baseband hardware.
The current discourse seems to be around these factors:
- Deploy less basebands of a more powerful hardware: instead of each cell site having its own baseband hardware, opt for a “baseband hotel” or cloud RAN model where the baseband is at a hub site and the radio heads are connected remotely through fiber.
- The efficiency and power saved from the AI baseband will make up for the higher initial cost. Power consumption savings, higher capacity served per site will allow the operator to recoup the higher initial investments
- The AI baseband will cost more than traditional RAN but operators will monetize the unused capacity by RAN by leasing out GPU as a service.
Trying to ground these in the current reality of the telecom industry, where operators are mostly shrinking their budgets for new deployments specially after spending a lot on 5G infrastructure over the past 5 years, I do not see this additional CAPEX injection happening with the expectation of “build it and they will come” that has motivated the telecom industry since the 1990s.
Possible emerging models
What I can assume will happen give the current economic realities is a mix of the following scenarios:
- Partnerships between Telcos and Hyperscalers: Hyperscalers like AWS, Google Cloud, Microsoft Azure have already the hardware abstraction expertise and the market place for the potential demand on “GPU as a service”. Telcos can accept a share of the revenue in exchange for hosting the GPUs deployed on their cell or edge sites.
- Telco Network as a service: This scenarios assumes other parties become interested in owning the telecom infrastructure entirely and renting it out to virtual network operators (VNO) and to AI workload customers similarly. Potential candidates for this are, once again, the hyperscalers and possibly some of the bigger “tower companies” that may want to integrate vertically in the market. This has some similarities to early ideas for 5G deployment where some countries wanted to build one shared 5G network that all operators would utilize in a network sharing approach.
- Enterprise and private telco networks focus: yet another implementation “for AI and RAN” is for it to be limited to specific industrial, enterprise or governamental campuses. By limiting the extent of the investment in AI ready infrastructure to where the demand actually is, this could help make a more surgical investment plan, assuming the telcos could pull this off quickly enough before hyperscalers can deploy their own edge solutions.
- Full Pivot to Regional Data Center player: This might happen with a few select players, will require orders of magnitude of CAPEX investments but could be a way for telcos to finally stop being just dumb pipes. A proper catalyst exists for this model in the form of the need for sovereign AI platforms and concerns about data privacy and the need to develop local and customized AI models.

Leave a comment