
This post aims to present a new form of communications using mobile telecom networks (4G, 5G and beyond) by leveraging the multimodal generative AI capabilities to bridge the gaps between hearing challenged, speech challenged, sight challenged and other users. The main concept is that the user device would indicate to the network intelligent controller what modal of communication is preferred and that would allow the network to use the communicated message as an input to a LLM agent sitting on the network edge (cell site or hub site) and infer the required form of delivered communication to the end user accordingly.
Multimodal messaging use case for accessibility
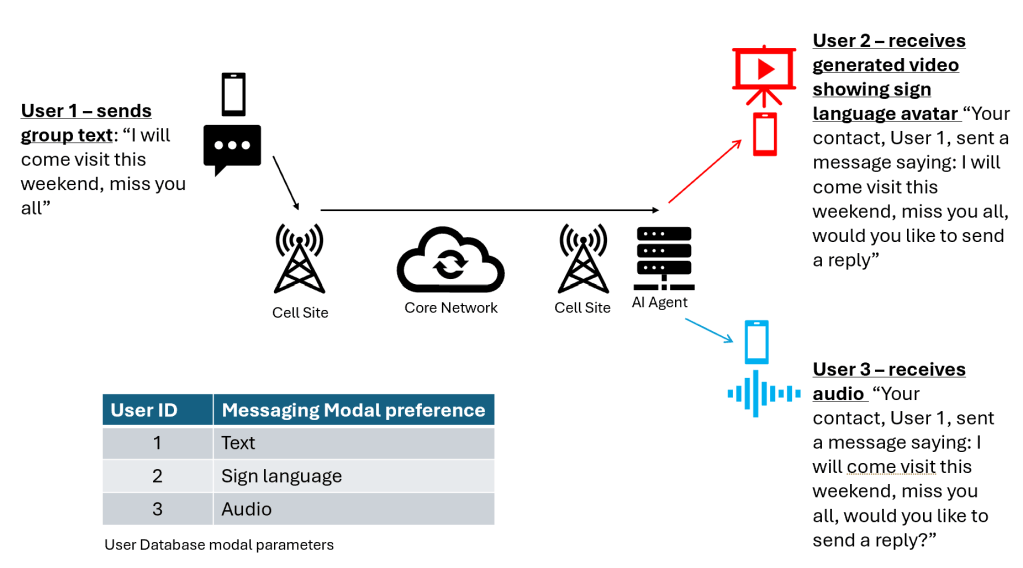
In this first messaging use case, user 1 has a modal preference of text messaging, user 2 has a hearing/speaking disability and requires all communications in sign language while user 3 is eye sight challenged and requires messages to be in audio format. User 1 decided to send a group message to 2 of his old friends he is planning to visit in the weekend.
The mobile network, enhanced with AI capability on the edge, can implement an AI multimodal agent that would be able to lookup the user modal preference on the user database (CUDB, HSS) and upon receipt of a text message from user 1, would trigger the AI agent to generate a video of the message content through an Avatar using sign language so that User 2 can perfectly understand user 1’s message and also capture through user 2’s camera if they want to respond back.
In a similar fashion, the AI agent would know that User 3 requires an audio message and do the necessary text to speech generation of the message and also offer to reply back based on the voice input of User 2.
This can be enabled with RAN network evolving to be able to handle AI workloads on the cell site, allowing it to host the necessary AI agent using multimodal Large Language Model locally to reduce latency which is less sensitive in a messaging application but allows an improved quality of connectivity and accessibility to different users with different needs.
The parameter indicating the preferred modality of communication for each user can be configured from the user device during initial configuration and stored in the user database (HSS for example) so that the network remains aware of this preference.
Multimodal calls use case for accessibility
In a similar way we can extend this idea of a multimodal message to the multimodal phone call between parties with different accessibility needs.
If User 1 calls User 2 who has a hearing disability, the network will trigger the AI agent on the edge site to generate a sign language avatar video and communicate the call accordingly. This would have some more demanding latency needs compared to the messaging use case but will be a great tool of inclusivity and to enhance the quality of life for User 2.
Implementation
The implementation of these concepts would require that the AI inference has access to the user plane data in the form of the messaging or call content initiated by user 1 towards their recipient(s) which is not something typically allowed in traditional telecom networks, specially at the cell site level, obviously this could open up a whole vulnerability and attack surface on the AI workload engine’s level. However if we consider a new service definition and the possibility to integrate the same Digital Unit (DU), Control Unit (CU) and AI inference on the same hardware this could open the way to more secure implementation.
Alternative implementation could be in the IP Multimedia Subsystem (IMS) however this could lead to further delays due to centralization of the Core IMS away from the end users.
Yet another implementation could be on the user device level, today it is not fully feasible as running LLM locally on a current (2025) is possible but not providing a real time performance expected from such a service, however we can envision in a few years and with more specialized multimodal LLM we could see it happen to some degree.
Next Steps
The modeling of the multimodal communication as a first prototype can be done with existing LLM using a simple agent architecture that receives the incoming call/message and depending on the destination user preferences does the necessary modal transformation using the LLM and the appropriate prompting for each mode.
The integration of this into the Radio Access Network (RAN) can be further studied in a lab environment to identify how best to integrate it, which node levels would be best suited to host it (cell site CU, DU or RAN Intelligent Controller) and what customization will be needed for future standards and software implementation to make this happen.

Leave a comment